Sync data from S3 to File
Trusted by




Get a personalized demo
Book a demo and see how quickly CloudQuery delivers new and ongoing insights on your multi-cloud environments.



Enterprise Ready
Customize & Extend
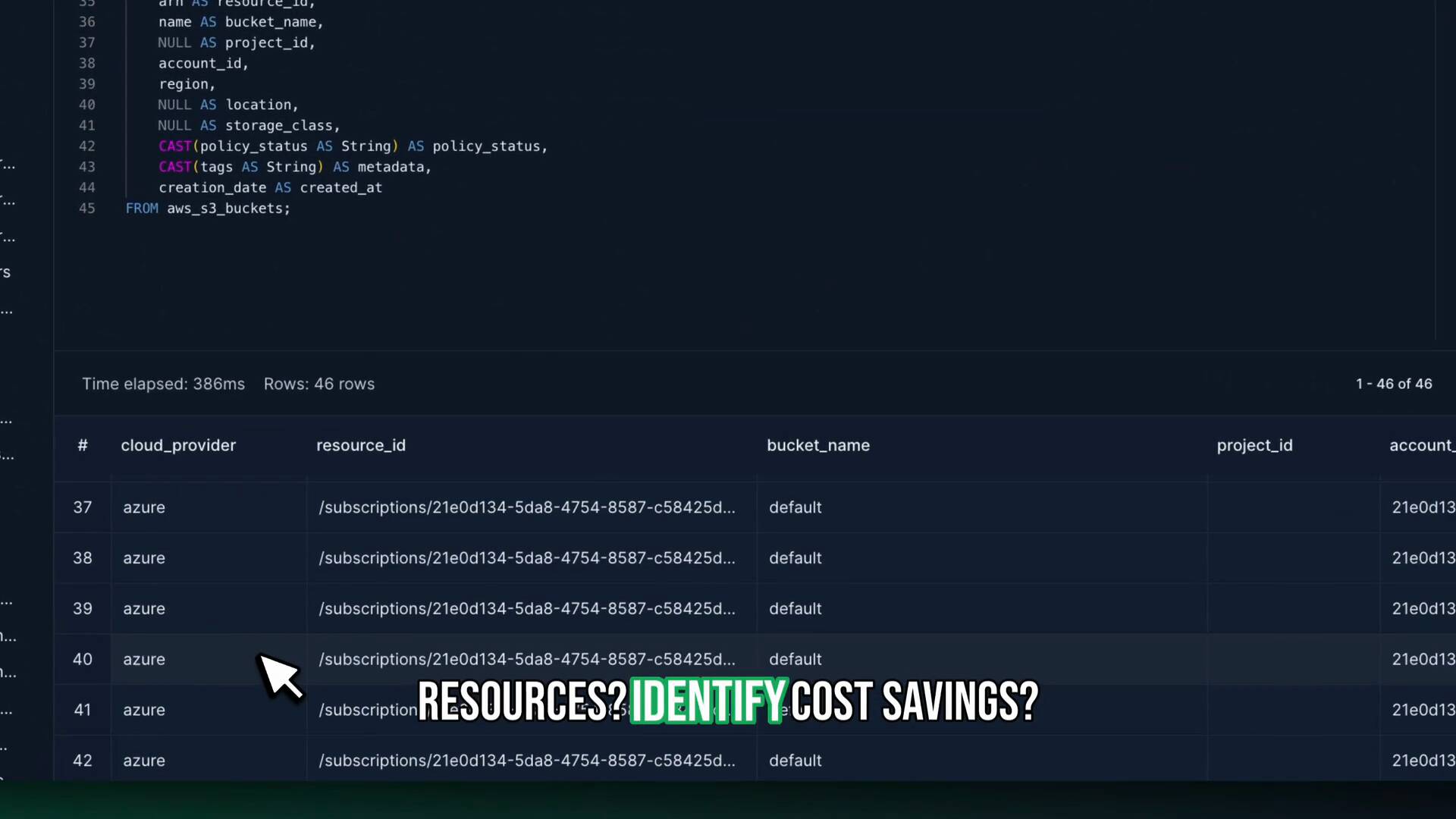
Query Assets with SQL
Non-invasive account access for better security and efficiency.
Import data with CloudQuery SDKs and build your own plugins.
Query cloud assets and security with a simple SQL-based UI.
Step by step guide for how to export data from S3 to File
Table of Contents
Windows Setup
Step 1: Install CloudQuery
To install CloudQuery, run the following command in your terminal:
curl -L https://github.com/cloudquery/cloudquery/releases/download/cli-v6.20.5/cloudquery_windows_amd64.exe -o cloudquery.exe
Step 2: Create a Configuration File
Next, run the following command to initialize a sync configuration file for S3 to File:
cloudquery.exe init --source=s3 --destination=file
This will generate a config file named s3_to_file.yaml. Follow the instructions to fill out the necessary fields to authenticate against your own environment.
Step 3: Log in to CloudQuery CLI
Next, log in to the CloudQuery CLI. If you have't already, you can sign up for a free account as part of this step:
cloudquery.exe login
Step 4: Run a Sync
cloudquery.exe sync s3_to_file.yaml
This will start syncing data from the S3 API to your File environment! 🚀
See the CloudQuery documentation portal for more deployment guides, options and further tips.